Monitoring MongoDB User Experience on SCOM
Cloud application requirements have pushed beyond the limitations of relational database management systems. As one of the classical NoSQL databases, MongoDB is a powerful tool helping companies align with new cloud-based business strategies.
Ensure a perfect Digital User Experience.
Ease daily administration efforts, and get pinpoint information on how to improve performance. Built-in, secure reporting options will help you and your team make better decisions for future expansions.

By loading the video, you agree to YouTube's privacy policy.
Learn more
Benefits
Deliver outstanding performance and availability by advanced MongoDB monitoring.
The NiCE MongoDB Management Pack is a sophisticated and intelligent Enterprise Ready Management Pack designed to integrate into Microsoft SCOM.
Increase the productivity of the MongoDB Operations Manager administrator and operator. Identify problems quickly and take corrective action to avoid costly downtime. Built-in features like SCOM “Diagnostic Tasks” help the DBA and the operator to troubleshoot more efficiently.
Get a sophisticated MongoDB monitoring integration into Microsoft System Center Operations Manager. No need to install or configure additional server proxies or connectors to pinpoint root causes. Solve issues easily, quickly, and efficiently with no additional software on the Management server or proxy.
No extra agents are required. Built on the original System Center Agent providing you with the best of Agent-based monitoring for MongoDB.
Centrally configure exception-biased monitoring in distributed MongoDB environments. No run-time data is stored on the SCOM server or Oracle. Run-time data is stored in the Operations Manager Database and Data Warehouse.
The NiCE MongoDB Management Pack will help you reduce the complexity of managing your MongoDB environment by intelligent event correlation and dashboarding.
End-to-end Mongo DB management
End-to-end management of your MongoDB databases is of utmost importance. Key functions required:
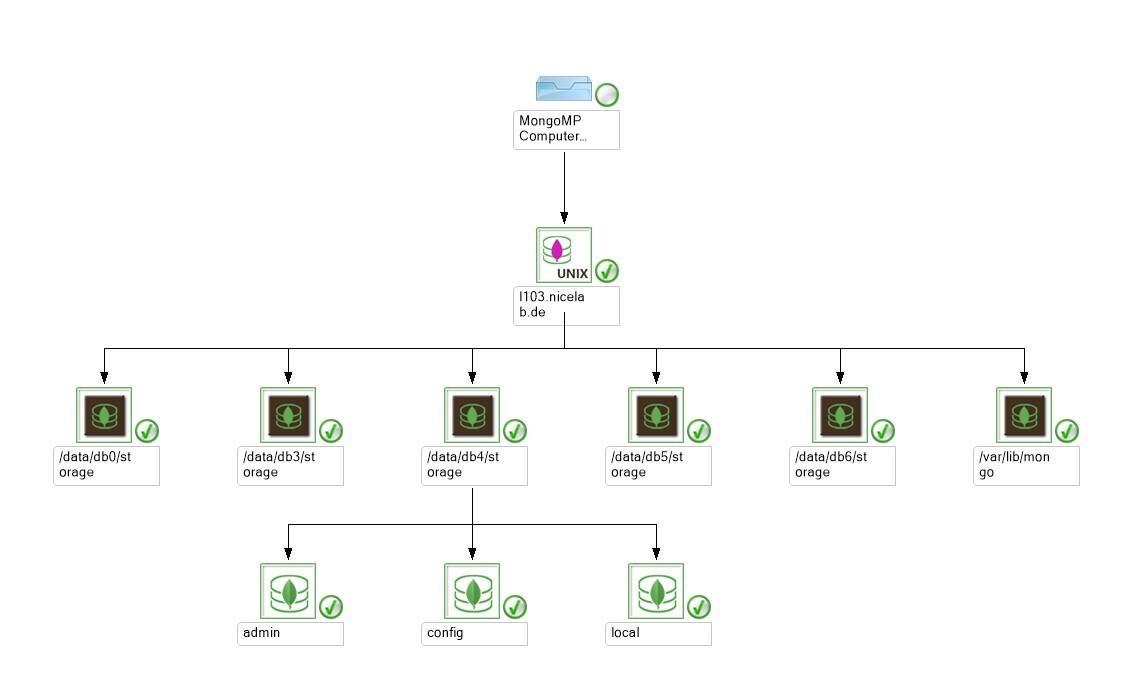
Discovered MongoDB environment using the NiCE MongoDB Management Pack for Microsoft SCOM.
Features
The NiCE MongoDB Management Pack increases your operational efficiency and reduces the total cost of ownership in the long run.
As a Microsoft Gold Business Partner, we provide you with the most up-to-date, fully functional Management Pack.
Rely on Microsoft proven monitoring technology. No additional monitoring adjustment is needed. Simply put up the Microsoft agents for high availability.
Clearly understand the business impact of MongoDB alerts and align IT operations and services with business needs. Get auto-discovery and diagram views of the MongoDB topology.
Save time and money by monitoring and managing your whole environment from a single point of reference. Standard databases and instances views, as well as cluster views, complete a holistic monitoring approach. Replica Sets, Cluster, and other setups are included.
Easily understand what server, backup, and recovery power is needed to ensure adequate performance within the required time constraints by using the built-in MongoDB Performance Views.
Precise On-Time Availability Alerting via System Center channels and subscriptions. The alerting is done precisely through a number of core monitors. The NiCE MongoDB Management Pack provides separate availability monitors for Listeners, Instances (Processes), Databases, Tablespaces, and Datafiles.
Log monitoring is vital when availability needs to be guaranteed and improved. Including these details into monitoring will scale up the availability of your MongoDB databases.
Mission-critical workloads require consistent performance. Good SLA reporting helps to manage, monitor, and modify resources the right way at any time.
FAQ
Get answers to the most frequent questions regarding the NiCE MongoDB Management Pack for SCOM
The NiCE MongoDB Management Pack supports Microsoft SCOM 2016, 2019, 2022, and Azure Monitor SCOM Managed Instance.
The NiCE MongoDB Management Pack supports MongoDB 3.6, 4.0, 4.2, and 4.4
running on RHEL 6.2, 7, and 8, or SLES 12, and 15
The NiCE MongoDB Management Pack is licensed per MongoDB Instance.



Start advanced MongoDB Monitoring now
Please send us your request via the webform. We are looking forward to receiving your request.
Kind regards and keep on rocking,
Your NiCE IT Management Solutions Team